山本ワールド
円周率計算プログラム(多倍長整数による計算)(32/64bit)(工事中)
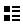
ガウス=ルジャンドルのアルゴリズム
初期値
反復式
πの算出
多倍長整数を用いて円周率を計算する
32bit整数型の配列で多倍長を表現する
C++の32bit整数型は用いる場合、たとえば足し算で32bitどおし値を足した場合、32bitにおさまらなくなります。アセンブラの場合桁あふれをキャリーフラグで検出できますが、C++の場合できませんので足し算する前の数字のビット数をあらかじめ押さえておく必要があります。今回は、符号ビットと桁あふれ検出のため計2ビットを使用することとし、30bitを1桁とします。表現できる数値の範囲は、0~1,073,741,823(10進数で10桁弱)です。
多倍長整数はリトルエンディアンで格納します。
整数の計算しかできないので、小数点を表現するために求めたい桁数より大きい2進数で切りのよい数字をあらかじめ乗算して計算します。
最後に10進数に戻すときは、100,000,000進数に変換してから10進数として保存します。
本プログラムの円周率計算は非常に遅いです。
加算
筆算と同様に下位の桁から加算,br /します。桁あふれがあった場合、次の上位の桁に1を加算します。関数はladdn,laddi,lincです。
これらの関数の違いは、末尾nの関数が多倍長どおし、末尾iが多倍長と30bitどおしの計算となります。
減算
筆算と同様に下位の桁から減算します。桁どおしの計算結果が負となった場合は、その桁に1,073,741,824を加算して上位2bitをクリアします。次の上位桁から1を引きます。関数はlsubn,lsubi,ldecです。
これらの関数の違いは、末尾nの関数が多倍長どおし、末尾iが多倍長と30bitどおしの計算となります。
乗算
筆算と同様に1桁ずつ計算し加算します。関数はlmuln,lmuliです。
これらの関数の違いは、末尾nの関数が多倍長どおし、末尾iが多倍長と30bitどおしの計算となります。
除算
多倍長/30bit(ldivi関数)
筆算と同様に上位桁より割り算を実施しその商を、計算結果の上位の商とし、余りを次の下位の桁と合わせてさらに割り算を実施します。したがってC++の標準の割り算を順番に実施すれば求められます。多倍長/多倍長(ldivn関数)
この場合、商の上位桁より被除数の上位桁/除数を順番に求めなければなりませんが、多倍長の割算を小さい値の割算に変換する方法はありません。したがって、被除数の上位桁と除数の上位桁の割算を実施し商の近似値を得てこの仮商と除数を掛け合わせ被除数から引くことにより余りが求められますのでこの余りが除数より小さくなるまで仮商-1を実施すれば真の商が計算できます。仮商の精度を高める方法としてKnuth Dの方法があります。
別のアプローチとしてニュートン法により近似していく方法があります。
ここではKnuth Dアルゴリズムを使用しました。
多倍長整数の例
多倍長整数 a[2]=1,a[1]=0,a[0]=0 で1,073,741,824進数は10進数で表わされるリトルエンディアンの数値を変換すると下記のとおりとなります。1*1,073,741,824^2+0*1,073,741,824+0=00000115,29215046,06846976となります。
平方根の計算(lsqrt関数)
Aの平方根は下記の式で反復すると近似できる初期値は
最上位桁よりsqrt関数で求めた値を使用しました。
実行結果
計算結果は、longpi.txtに保存されます。ファイルの中身はスーパーπと同形式です。1,000桁計算した場合 i7-3820(4.2GHz) 64bit実行ファイルで計算に0.007秒 小数点以下1,000桁までスーパーπと一致しました。
10,000桁計算した場合 i7-3820(4.2GHz) 64bit実行ファイルで計算に0.848秒 小数点以下10,000桁までスーパーπと一致しました。
100,000桁計算した場合 i7-3820(4.2GHz) 64bit実行ファイルで計算に129.849秒 小数点以下100,000桁までスーパーπと一致しました。
1,000,000桁計算した場合 i7-3820(4.2GHz) 64bit実行ファイルで計算に16177.278秒(4時間29分37.278秒) 小数点以下1,000,000桁までスーパーπと一致しました。
計算桁数によって最下位より数桁の誤差が生じることがあります。
コマンドプロンプトでの実行結果(CPU i7-3820) 10,000桁
以下に64bitとしてコンパイルした場合とと32bitとしてコンパイルした場合それぞれの実行結果を記します。Windows 7 64bit RAM 16GB
実行時間の大半を割算が占めています。64bitと32bitを比較すると特にlmuliとldiviの実行結果が顕著に違っています。
lmuli
32bit×32bitの結果が64bitとなります。C++では結果が64bitとなるため64bit*64bitで計算しなければなりません。32bit版ではスタックに合計で16byteの引数を積んで__allmulという関数を読んでいます。64bit版ではimul rax,rcxで計算できます。アセンブラで記述すれば32bit版でも1命令で32bit*32bit=64bitの計算ができますので高速化が可能です。面白いことに64bit版の32bit符号無の掛け算が符号付きであるimulが使われます。ちなみに32bit版/64bit版で16bit*16bitの符号無計算をする場合もimul命令が使われています。割り算では符号無のdivが使われます。理由はよくわかりませんが、32bitの整数型を使いながら2bit除いて30bitを有効数値として使用しているのはこの性です。31bit使用すると桁あふれが生じた場合、負と認識されおかしな結果になるからです。
; 754 : a = (BASE_DINT)dtc[n] * (BASE_DINT)src + c; 32bit版でコンパイル(Visual C++ 2008 Standard Edition)した場合のアセンブラ出力
00043 8b 54 24 24 mov edx, DWORD PTR _src$[esp+20]
00047 8b 0c 2b mov ecx, DWORD PTR [ebx+ebp]
0004a 33 c0 xor eax, eax
0004c 50 push eax
0004d 52 push edx
0004e 50 push eax
0004f 51 push ecx
00050 e8 00 00 00 00 call __allmul
00055 03 c6 add eax, esi
00057 13 d7 adc edx, edi
; 754 : a = (BASE_DINT)dtc[n] * (BASE_DINT)src + c; 64bit版でコンパイル(Visual C++ 2008 Standard Edition)した場合のアセンブラ出力
00050 8b 04 17 mov eax, DWORD PTR [rdi+rdx]
00053 48 83 c2 04 add rdx, 4
00057 48 0f af c1 imul rax, rcx
0005b 49 03 c1 add rax, r9
ldivi
ldiviでもlmuliと同様の事情があります。
; 818 : ans[j]=unsigned((d+r)/src); 32bit版でコンパイル(Visual C++ 2008 Standard Edition)した場合のアセンブラ出力
00059 03 c3 add eax, ebx
0005b 13 ce adc ecx, esi
0005d 33 d2 xor edx, edx
0005f 52 push edx
00060 8b 54 24 38 mov edx, DWORD PTR _src$[esp+40]
00064 52 push edx
00065 51 push ecx
00066 50 push eax
00067 e8 00 00 00 00 call __aulldvrm
; 818 : ans[j]=unsigned((d+r)/src); 64bit版でコンパイル(Visual C++ 2008 Standard Edition)した場合のアセンブラ出力
00055 33 d2 xor edx, edx
00057 48 03 c3 add rax, rbx
0005a 48 f7 f5 div rbp
0005d 48 8b da mov rbx, rdx
00060 89 01 mov DWORD PTR [rcx], eax
64bit
a 0:回目 0.000000秒
1:回目 0.171000秒
2:回目 0.264000秒
3:回目 0.342000秒
4:回目 0.420000秒
5:回目 0.483000秒
6:回目 0.545000秒
7:回目 0.623000秒
8:回目 0.679000秒
9:回目 0.720000秒
10:回目 0.753000秒
11:回目 0.780000秒
12:回目 0.800000秒
13:回目 0.820000秒
14:回目 0.828000秒
15:回目 0.835000秒
πの計算時間は 0.848000秒 10000桁
πの保存時間は 0.007000秒 10000桁
laddiの実行時間は 0.000000秒 0回
laddnの実行時間は 0.000000秒 136回
lsubiの実行時間は 0.000000秒 0回
lsubn_cppの実行時間は 0.611000秒 134471回
lmuli_cppの実行時間は 0.185000秒 134485回
lmulnの実行時間は 0.052000秒 51回
ldiviの実行時間は 0.002000秒 1399回
ldivnの実行時間は 0.796000秒 121回
32bit実行ファイル(64bit Windows)
a 0:回目 0.000000秒
1:回目 0.301000秒
2:回目 0.440000秒
3:回目 0.544000秒
4:回目 0.653000秒
5:回目 0.793000秒
6:回目 0.903000秒
7:回目 0.996000秒
8:回目 1.074000秒
9:回目 1.137000秒
10:回目 1.183000秒
11:回目 1.230000秒
12:回目 1.261000秒
13:回目 1.303000秒
14:回目 1.314000秒
15:回目 1.326000秒
πの計算時間は 1.349000秒 10000桁
πの保存時間は 0.018000秒 10000桁
laddiの実行時間は 0.000000秒 0回
laddnの実行時間は 0.000000秒 136回
lsubiの実行時間は 0.000000秒 0回
lsubn_cppの実行時間は 0.778000秒 134471回
lmuli_cppの実行時間は 0.499000秒 134485回
lmulnの実行時間は 0.067000秒 51回
ldiviの実行時間は 0.015000秒 1399回
ldivnの実行時間は 1.281000秒 121回
longpi.txtの例
大容量なので先頭から数行のみ記載しております。1,000,000桁の実行結果のファイルは以下からダウンロードしてください。longpi1000000.zip
PI=3.
1415926535 8979323846 2643383279 5028841971 6939937510
5820974944 5923078164 0628620899 8628034825 3421170679
8214808651 3282306647 0938446095 5058223172 5359408128
円周率計算プログラム ソースコード・実行ファイル
longpi1.zip2013/07/11 除算関数ldivn_knuth_dの剰余の桁数が真値より大きくなる現象を修正。円周率の答えには影響ない
検証
計算結果の結果の検証は手を抜いてスーパーπの計算結果が格納されるファイルであるpi.datと比較することにより確認しました。確認用に下記のプログラムを作成しました。単純にファイルの先頭からlongpi.txtとpi.datを比較し違いがある場合にその桁数を表示します。
ソースコード・実行ファイル
pichk.zip考察
計算は非常に遅い。速くするには、アセンブラによるチューニング(32bitのうちC++では30bitのみ使用しているのに対してアセンブラにより32bitサポートとなる。また64bitを前提とすれば1桁で表現できる範囲が広がるので計算の効率化が図れる)
乗算をFFTで計算する。コーティングはSSEを用いる。
一番時間を要する除算はニュートン法で置き換える。
たとえば100万桁の計算をする場合、最初から100万桁から計算するのではなく、必要桁数のみで計算する。(擬似的な浮動小数点をサポート)
などが考えられます。